void findVinArray(int a[l, int n, int v) {
1: int i = 0;
2: int count = 0;
3: while (i < n) {
4: if (a[i] == v)
5: count+t;
6: i++;
}
7: printf ("number %d", count);
}
(예제 프로그램)
아래 표는 위 코드를 제어 흐름 그래프로 나타내기 위해 기본 블록들을 식별한 것이며
이를 제어 흐름 그래프로 나타낸 것이 제어 흐름 그래프의 예의 그림이다.
기본 블록
기본 블록
문장
진입점
진출점
B1
{1, 2}
1
2
B2
{3}
3
3
B3
{4}
4
4
B4
{5}
5
5
B5
{16}
6
6
B6
{7}
7
7
기본 블록 Bl은 1 2번 문장들로 구성되어 있다.
3번 문장이 B1에 속하지 않는 이유는 0번 문장의 실행이 종료되면
3번 문장으로 제어가 이동되어야 한다.
따라서
3번 문장은 1번 문장과 2번 문장과 동일한 블록에 포함될 수 없다.
또한,
3번 조건에 의해 조건이 참이 되면 4번 문장이 실행되나
거짓이 되면 4번 문장은 실행되지 않는다.
진출점이 두 개가 되기 때문에 3번과 4번 문장은
하나의 블록에 포함되지 않는다.
다른 기본 블록도 마찬가지로 구성된다.
아래 제어 흐름 그래프의 예 그림에는
기본 블록 간의 실행 순서를 고려하여
제어 흐름 그래프로 나타낸 것이다.
제어 흐름 그래프에서 볼 수 있듯이
프로그램 실행 흐름 및 프로그램 구조가
일목요연하게 나타나 있음을 알 수 있다.
제어 흐름 그래프 예
제어 흐름 그래프상에서 입력 간선이 없는 노드를
시작 노드라 하고, 출력 간선이 없는 노드를 종료 노드라 한다.
위 그림에서 시작 노드는 B1, 종료 노드는 B6이다.
제어 흐름 그 래프상에서 프로그램 경로(Path)는
시작 노드에서 종료 노드까지 일련의 노드들이다.
예로 (B1, B2, B3, B4, B5, B2, B3, B5, B2, B6)는
프로그램상에 존재하는 수많은 프 로그램 경로 중의 하나이다.
구조 기반 테스트의 이해
가장 이상적인 구조 기반 테스트
프로그램의 모든 경로를 최소한 한 번은 실행하여 테스트하는 것이다.
그러나
불행하게도 모든 프로그램 경로를
한 번씩 실행시키는 작업은 현실 적으로 불가능하다.
그 이유는 프로그램 경로가 엄청나게 많이 존재할 수 있기 때문이다.
프로그램상에 존재하는 모든 가능한 경로를 테스트하는 대신
일부 경로만 테스트하는 방법을 사용한다.
대표적인 기본 경로 테스트인 문장 테스트, 분기 테스트,
조건 테스트, 다중 조건 테스트, MCDC 및 자료 흐름 테스트 등은
모든 프로그 램 경로를 테스트 하지 않고 일부 경로만 선정하는 기준을 제공한다.
문장 테스트
문장 테스트(Statement test)는 프로그램의
모든(실행 가능한) 문장을 최소한 한 번은 행하도록 요구한다.
문장 테스트는 그림 9.3의 절차로 수행된다.
(1) 테스트 대상 프로그램에 해당하는 제어 흐름 그래프를 작성한다.. (2) 모든 실행 가능한 기본 블록들을 지나가는 프로그램 경로 집합을 식별한다. (3) 프로그램 경로 집합에 있는 각 프로그램 경로에 대해 다음을 수행한다. A. 경로를 실행하는 입력 데이터를 식별한다. B. 명세 등에서 해당 입력에 대한 기대 출력(Bxpected output)을 식별한다.
(문장 테스트를 수행하는 절차)
위 테스트 절차로 제어 흐름 그래프의 모든 블록이 수행되었다면
당연히 프로그램의 모 문장이 수행되었음을 의미한다.
프로그램에 대해 문장 테스트에 따라 테스트 케이스를 설계해보자.
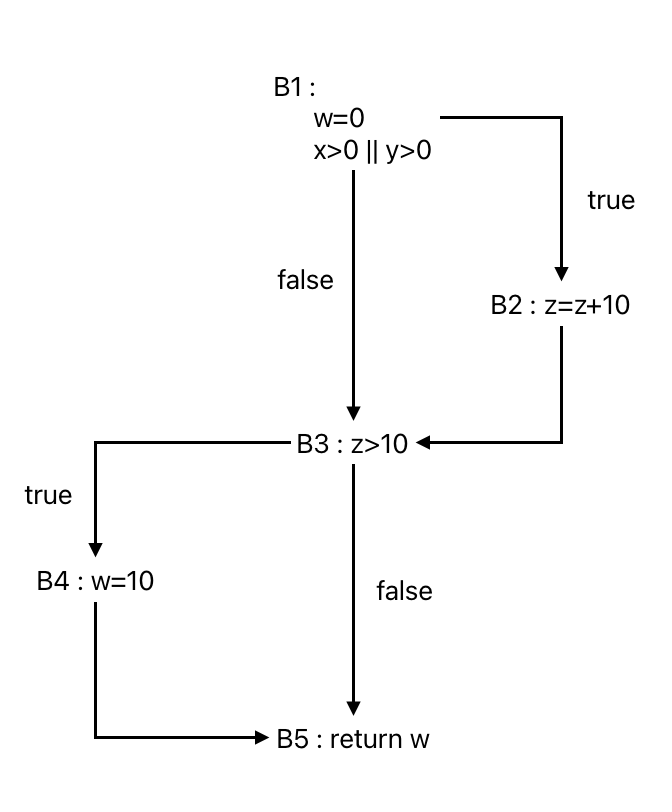
명세 함수 foo는 입력 x와 z 또는 y와 z가 양수이거나 x, y 값에 상관없이 z가 10보다 크면 10을 반환한다. 그 외의 경우는 0을 반환한다.
int foo(int x, int y, int z) {
int W=0;
if (x>0 || y›0)
z=z+10;
if (z>10)
w=10;
return w;
}
(1) 테스트 대상 프로그램에 해당하는 제어 흐름 그래프를 작성한다. (2) 아직 실행되지 않은 결정의 결과(들)에 도달하는 프로그램 경로 집합을 식별한다. (3) 프로그램 경로 집합에 있는 각 프로그램 경로에 다음을 수행한다. A. 경로를 실행하는 입력 데이터를 식별한다. B. 명세 등에서 해당 입력에 대한 기대 출력(Expected output)을 식별한다. (4) (2)-(3)을 모든 결정의 결과가 실행될 때까지 반복한다.
(결정 테스트를 수행하는 절차)
프로그램을 사용하여 결정 테스트에 따라
테스트 케이스를 설계 해보자.
이 프로그램에는 2개의 결정문이 있다. x>0 || y>0과 z>10, 각각의 결정문이 true와false 값을 갖는 프로그램 경로 집합을 구한다. 이러한 프로그램 경로 집합은 유일하지 않으며 여러 개가 존재할 수 있다.
int foo(int x, int y) {
boolean k;
1: k=(x>10)&&(y>10);
2: return k+1;
}
(프로그램 예제)
1번 배정문은 결정식 "(x> 10)&&(y> 10)"의
결과를 변수 k에 대입한다.
따라서
결정 테스트로 테 스트 케이스 집합을 구하면
k가 true와 false가 되는 경우를 모두 나오게 하는
x와 J의 값을 사용하여 테스트해야 한다.
즉, x와 y가 모두 10보다 큰 경우와 x나 y가 10보다 작은 경우인
두 개의 테스 트 케이스가 필요하다.
반면에 분기 테스트는 제어 흐름 그래프를 작성했을 때
기본 블록 하나로만 구성되므로 이 블록을 실행하는 테스트 케이스이면
k가 어떤 값을 가지든지 상관없다.
따라서
하나의 테스트 케이스이면
분기 테스트의 요건을 만족한다.
테스트 요건 간의 관계
포용 관계(Subsumption relation)로서 서로 비교할 수 있다.
만 약 두 개의 테스트 요건이 C1과 C2가 있다고 가정할 때
Cl을 만족하는 테스트 케이스 집합이 C2를 만족한다면
C1은 C2를 포용한다고 말한다.
동일한 프로그램에 대해
결정 테스트를 만족하는 테스트 케이스 집합은
문장 테스트를 만족함을 쉽게 알 수 있다.
따라서
결정 테스트는 문장 테스트를 포용한다.
조건 테스트
DO-178B는 항공전자 시스템에서 사용되는
소프트웨어의 FAA(미국연방항공국)승인을 위한 지침으로
널리 사용되어오고 있다.
DO-178B 결정과 조건의 구분
A Condition is a Boolean expression containing no Boolean operators. A Decision is a Boolean expression composed of conditions and zero or more Boolean operators. A decision without a Boolean operator is a condition. If a condition appears more than once in a decision, each occurrence is a distinct condition.
(1) 테스트 대상 프로그램에 해당하는 제어 흐름 그래프를 작성한다. (2) 아직 실행되지 않은 조건의 결과(들)에 도달하는 프로그램 경로 집합을 식별한다. (3) 프로그램 경로 집합에 있는 각 프로그램 경로에 다음을 수행한다. A. 경로를 실행하는 입력 데이터를 식별한다. B. 명세 등에서 해당 입력에 대한 기대 출력(Bx pected output)을 식별한다. (4) (2)-(3)을 모든 조건의 결과가 실행될 때까지 반복한다.
(조건 테스트를 수행하는 절차)
프로그램을 사용하여 조건 테스트에 따라 테스트 케이스를 설계 해보자.
이 프로그램에는 2개의 결정이 있다.
첫 번째 결정×>OIl y>0에는 x>0 과 y> 0인
두 가지 조건으로 구성되어 있고,
두 번째 결정에는 2>10인 조건 하나로 이루어져 있다.
아래 표는 조건 테스트를 만족하는 테스트 케이스 집합을 보여 준다.
테스트 케이스
입력
기대 출력
조건
x
y
z
x>0
y >0
Z>10
1
1
-1
0
0
true
false
false
2
-1
1
1
10
false
true
true
(테스트 케이스)
아래 식을 이용하여 테스트 케이스 집합에 의해
조건 테스트가 어느 정도 이루어졌는지
정량적으로 알 수 있으며, 이를 조건 커버리지 라고 한다.
조건 커버리지
더 알아보기
위 표에서 테스트 케이스 1은 총 6개의 결정 결과값 중에서
3개가 산출되기 때문에 6분의3 x 100=50%의 조건 커버리지를 갖는다.
여기에 테스트 케이스 "2"가 추가되면 100% 조건 커버리지를 갖는다.
조건 테스트는 결정 텍스트를 포용할까?
즉, 조건 테스트 요건을 만족하는 테스트 집합은
결정 테스트 요건을 만족할까?
대답은 No이다.
아래 표를 보면 쉽게 알 수 있다.
테스트 케이스
입력
기대 출력
조건
결정1
결정2
x
y
Z
x>0
У > 0
x> Olly >
z>10
1
1
-1
0
0
true
false
true
false
2
- 1
1
1
10
false
true
true
true
(조건 테스트를 만족하지만 결정 테스트를 만족하지 않은 테스트 케이스)
위 표를 보면 2개의 테스트 케이스로
모든 조건의 결과가 생성됨을 볼 수 있지만,
결정1은 true만 테스트 되고 false는 테스트 되지 않는다.
따라서
위 표의 테스트 케이스 집합은 조건 커버리지를 만족하지만,
결정 커버리지를 만족하지 않는다.
또한,
우리는 결정 커버 리지를 만족하지만
조건 커버리지가 반드시 만족되지 않는다는 사실을 이미 알고 있다.
따라서
조건 테스트와 결정 테스트는
서로 포용하지 않는다.
단축 연산과 조건 커버리지
단축 연산을 수행한다면
위 표의 테스트 케이스 집합은
100% 조건 커버리지를 만족하지 못한다.
아래 표는 단축 연산을 수행하는 경우
위 표의 테스트 케이스 집합에 따른 조건들의
평가 결과를 보여 준다.
아래 표에서 볼 수 있듯이 테스트 케이스 1은
x>0의 평가 결과로 전체 결정의 결과가 true가 됨을
알기 때문에 y>0 조건을 평가하지 않는다.
반면, 테스트 케이스 2는 x>0의 평가 결과가 false이기 때문에
결정의 결과를 알기 위해서는 y> 0을 반드시 평가해야 한다.
테스트 케이스
입력
기대 출력
조건
결정1
결정2
x
y
z
×>0
y>0
×>0||y>0
Z>10
1
1
-1
0
0
true
-
true
false
2
-1
1
1
10
false
true
true
true
따라서 테스트 케이스 집합은 조건 y>0에서
false가 나오는 경우가 없으므로
100% 조건 커버리지 를 만족하지 못한다.
100% 조건 커버리지를 만족하기 위해서는
y>0을 false가 되는 테스트 데이터를 추가할 필요가 있다.
이때, 주의할 점은
x> 0을 false가 나오도록 하면서
y>0을 false가 나오도 록 해야 한다.
만약, x> 0이 true가 나오면
5>0이 실행되지 않기 때문이다.
다음 표는 100% 조건 커버리지를
만족하도록 추가된 테스트 케이스를 보여준다.
테스트 케이스
입력
기대 출력
조건
결정1
결정2
x
У
z
×>0
y>0
×>0||y>0
Z>10
1
1
-1
0
0
true
-
true
false
2
-1
1
1
10
false
true
true
true
3
-1
-1
1
0
false
false
false
false
결정/조건 테스트
조건테스트에서 결정 테스트와 조건 테스트는
어느 쪽도 포용하지 않음을 기술하였다.
결정/조건 테스트(Decision Condition Test)는
결정 테스트와 조건 테스트를 모두 만족하는
테스트 케이스 집합을 설계하도록 요구한다.
(4) 테스트 대상 프로그램에 해당하는 제어 흐름 그래프를 작성한다. (4) 아직 실행되지 않은 결정과 조건의 결과(들)에 도달하는 프로그램 경로 집합을 식별한다. (3) 프로그램 경로 집합에 있는 각 프로그램 경로에 다음을 수행한다. A. 경로를 실행하는 입력 데이터를 식별한다. B.명세 등에서 해당 입력에 대한 기대 출력(Expected output)을 식별한다. (4) (2)-(3)을 모든 결정과 조건의 결과가 실행될 때까지 반복한다
int multi (int x, int y) i
if (×>0 && y <=-3) {
X=y+4;
}
return x;
}
(예시 프로그램)
이 프로그램에서 결정 "x> 0&&y<=-3"은
두 가지 조건 x>0과 y 〈=-3을 논리 연산자
"&&"를 사용하여 구성하였다.
다중 조건 테스트(Multiple Condition Tiest)는
아래 표에서 보인 바와 같이
두 가지 조건의 모든 가능한 조합에 대해
테스트 집합을 구성한다.
(다중 조건 테스트)
id
x>0&8y<=3
테스트 데이터
×>0
y<=ー3
1
true
true
(x: 10, y: -5)
2
true
false
(x: 10, y: -1)
3
false
true
(х: -5, у: -5)
4
false
false
(x: -5, y: - 1)
프로그램의 결정들에 사용된 모든 조건의 조합을
테스트할 수 있는 입력 데이터들을
테스트 데이터 집합으로 선정한다.
따라서
다중 조건 테스트는 문장 테스트,
결정 테스트, 조건 테스트 및 결정 조건 테스트를 포용한다.
(1) 테스트 대상 프로그램에 해당하는 제어 흐름 그래프를 작성한다. (2) 아직 실행되지 않은 조건의 조합을 실행하는 프로그램 경로들을 식별한다. (3) 프로그램 경로 집합에 있는 각 프로그램 경로에 다음을 수행한다. A. 경로를 실행하는 입력 데이터를 식별한다. B. 명세 등에서 해당 입력에 대한 기대 출력(Bxpected output)을 식별한다. (4) (2)-(3)을 모든 결정에 포함된 조건들의 조합이 실행될 때까지 반복한다.
(1) 프로그램의 모든 결정에 대해 (2)-(6)과정을 반복한다. (2) 주어진 결정을 트리 구조로 변환한다. (3) 트리를 따라 위로 올라갈 때 다음 과정을 루트 노드에 도달할 때까지 반복한다. A. 테스트 대상 조건 (간단히 테스트 조건)의 부모 노드가 OR이라면 형제 노드에게는 false를 할당한다. B. 만약 부모 노드가 AND라면 형제 노드에게는 true를 할당한다. (4) 트리 아래 방향으로 아직까지 값이 할당되지 못한 기본 조건들이 있다면 다음 과정을 통해 값을 전달 한다. A. 방문한 노드가 AND 노드이고 true라면 자식 노드는 모두 true가 되어야 하며, false라면 자식 노드 중 어느 하나는 false가 되어야 한다. B. 방문한 노드가 OR 노드이고 true라면 자식 노드 중 어느 하나는 true이며, false라면 자식 노드는 모두 false가 되어야 한다. (5) 테스트 조건의 진릿값을 true와 false로 각각 설정한 후에 다음을 수행한다. A. 트리의 각 조건에 할당된 진릿값을 생성할 수 있는 입력 데이터를 식별한다. B. 명세 등에서 해당 입력에 대한 기대 출력(Bxpected output)을 식별한다. (6) (2)-(5)과정의 결정을 구성하는 모든 조건에 대해 반복한다.
(MCDC 테스트를 수행하는 절차)
더 알아보기
다음 프로그램에 대해 MCDC 테스트 요건을
만족하는 테스트 케이스를 구해보자.
명세 함수 mcdc는 입력 x와 y가 모두 양수이거나
x, y 값에 상관없이 2가 10 보다 크면 20을 반환한다.
그 외의 경우는 10을 반환한다.
int mcdc(int x, int y, int z) {
int W=10;
if ((x>0 && y›O) || z>10)
W=W+10;
return w;
}